 backup
backup
Contrary to the popular belief that anything online stays online, the internet doesn’t remember everything. In a previous post in this series, we examined no fewer than nine scenarios in which you could lose access to online content. We also provided a detailed guide to what information you absolutely must (and preferably quickly) back up to your computer and how to do it. Today, we’ll discuss how to easily save web pages to your computer, how to organize these archives, and what to do if your favorite site has gone AWOL.
Let’s say you want to save a blog post with a recipe, compile a bibliography for your research paper, or even preserve a specific online publication for legal purposes. All of the above are published as web pages — which have a tendency to disappear at the wrong moment. Want to reminisce about music news and gossip from 2005? Good luck with that — the MTV News site shut down and all its articles and interviews are no longer available. Check references in Wikipedia articles? 11% of them lead nowhere, even though they were working when the article was published. This phenomenon of “link rot” — the gradual deletion or relocation of online content — is rapidly becoming a major problem. 38% of pages that existed ten years ago are no longer accessible today. So, if there’s a web page out there that you like or need, the wise move would be to create a backup.
How to save a web page to your computer
Since a web page consists of dozens or even hundreds of files, backing it up will require a bit of effort. Here are the main ways to do it:
Save only the text as an HTML file. Select the “Save page as…” menu command or button in your browser and then select “Webpage, HTML Only”. This will only save the text of the web page, without any graphics or other eye candy.
Save text and images. The “Webpage, Complete” option will create, besides an HTML file, a folder with the same name containing all graphic elements, styles, and scripts from the page. A downside of this option is that saving a lot of auxiliary files clutters your drive. The “Webpage, Single File” option is more convenient, bundling the web page and all its resources into a single .mhtml file. This will open freely in Chrome or Edge, but other browsers may have issues. This option is not available in all browsers, but if you install the SingleFile extension (available for most browsers), you can save the entire web page and its media content as a single HTML file that opens perfectly fine in all modern browsers.
Print to PDF. To preserve the main content of the page, but scrap menus and banners, your best option is Print to PDF. The resulting file will open on any computer.
With any of these options, make sure that the main text that you actually want to keep is still readable when you open the document.
An easier way to save a web page
The methods described above are a bit time-consuming and create clutter on your hard drive. For greater convenience, use a dedicated service such as Pocket (formerly Read It Later), wallabag, or Raindrop.io. They all work the same way: you send a link from which the service retrieves a document with all the illustrations, cleans the page of anything unnecessary, and saves it in your personal online storage. Even if the original page gets deleted or modified, the version you want will remain in your archive. These services allow you to group and sort your links, search for text inside, and view your saved pages on any device. For desktop, there’s an extension available for all the major browsers; and for mobile, there’s an app.
All these services offer an “eternal” archive only with a premium subscription, meaning you’ll have to pay for the convenience. That said, Wallabag is open-source — you can install it on your own server and not pay for third-party services or worry about the service getting shut down.
Some note-taking apps can also save complete web pages. These include Evernote, where the feature is called “Web Clipper”.
How to save a web page for others
If it’s not just a copy for yourself that you need, but to share a certain version of the page with others, you’ll need a public-archiving service.
The best-known is the Internet Archive (archive.org) and its Wayback Machine. Other options include archive.today (aka archive.is), perma.cc, and megalodon.jp. They all work on a similar principle: either at the user’s request or automatically they visit web pages and save a copy on their servers.
To request archiving of a web page, go to web.archive.org and enter the full address in the Save Page Now box. After you click Save, a window appears describing all of the page’s loaded components, followed by a permanent link to the site in its preserved state. It looks like this: https://web.archive.org/web/20240924045754/https://www.kaspersky.com/blog. The link shows both the address of the saved page and the exact time of saving — perfect for archival purposes.
Registering on archive.org lets you manage a collection of such links, take screenshots of saved sites, and download copies of them in the special web-archiving format.
On archive.org, you can view previously saved versions of websites and save the current state of any site — for example, our blog
On opening the archive link, you’ll see the saved page with a timestamp indicating when the snapshot was taken. This feature is useful for tracking and demonstrating changes in website data: price fluctuations, product description updates, edited news reports, and deleted information. The latter is particularly important for historical and cultural researchers based on defunct websites. Below, you can check out one of the first versions of GeoCities, a once popular web-hosting service that let you create “home pages”, express yourself, and find friends with shared interests long before social networks. It’s only thanks to the Wayback Machine that we can see it now — the site closed shop in 2016.
A gift for the old-timers: one of the earliest versions of GeoCities.com
How to find deleted internet content or an old version of a website
To view an old version of any website:
- Open archive.org.
- Enter the full address of the website or a specific page in the box next to the logo and click Enter. If the exact URL is unknown, you can enter the name of the website or words that describe it well.
- Select the desired website from the list. The results show at a glance how many copies are archived and for what period.
- Use the calendar to select which of the saved copies of the site you wish to view. Dates for which there is a saved copy are circled — the larger the circle, the more copies were made that day.
- Click the desired date and inspect the saved site. Note that loading a copy from the archive may take a few minutes.
- The calendar graph above the site copy lets you navigate to older and newer copies.
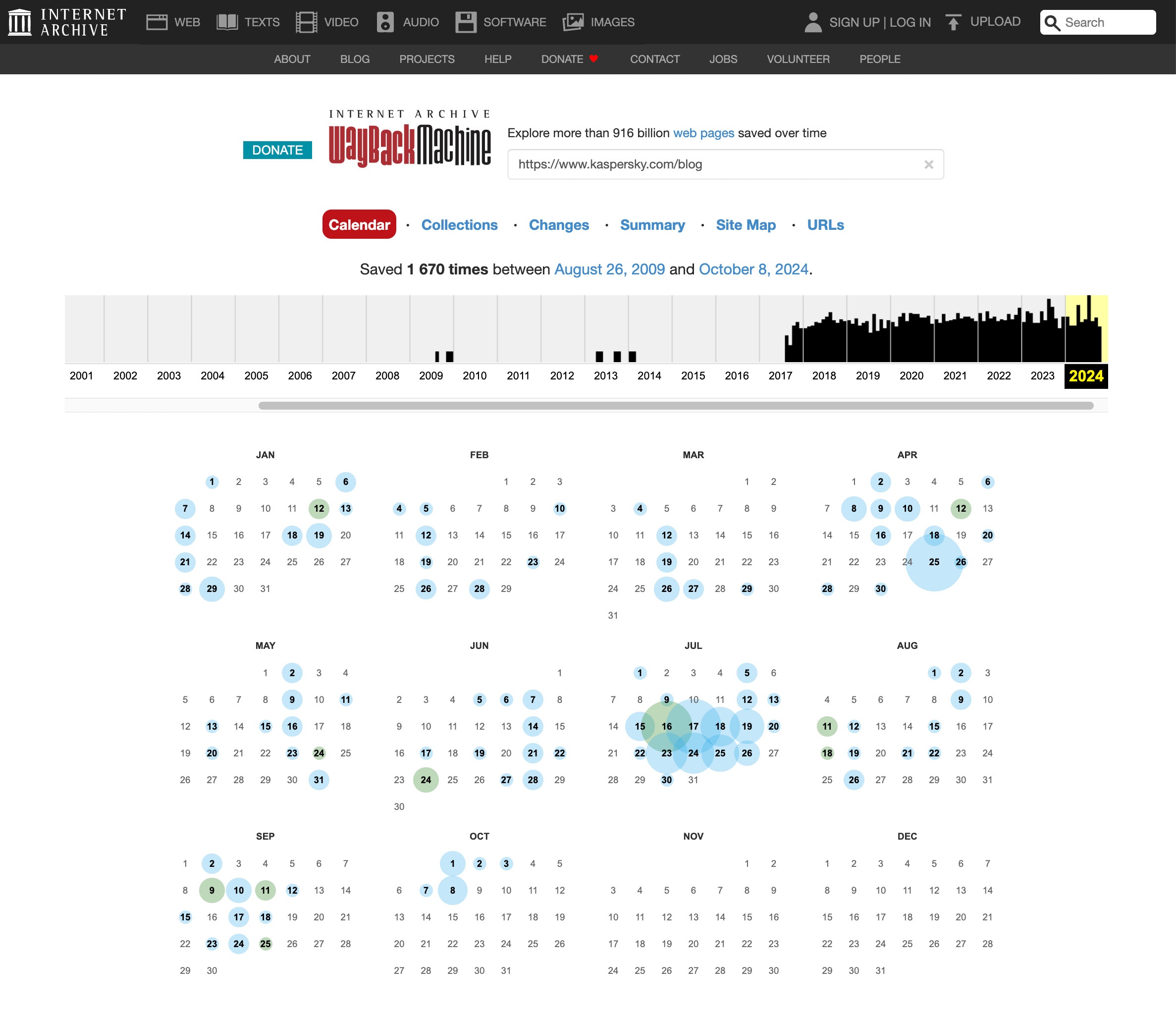
How to explore old versions of sites at web.archive.org
You can copy the link to the retrieved copy from the address bar to access the archived site directly, bypassing the search interface.
What if archive.org can’t help
The foundation behind archive.org sometimes complies with the requests of copyright holders and other authorized parties to exclude certain sites from the Wayback Machine. Also, the service never aimed to preserve the entire internet, so it may happen that the page you need was never indexed. In such cases, try looking for it in other time capsules.
Archive.today (aka archive.is) doesn’t automatically save pages — it does so only at the request of users. Among other things, this does away with having to follow instructions for search robots (robots.txt), and means that the archive contains documents that aren’t available in the Wayback Machine.
Another important web-archiving project is perma.cc, created by a consortium of major world libraries. However, it’s only free for participating organizations. Individual users can subscribe to a paid plan, with pricing based on the number of archived links.
A powerful alternative to specialized archives is search engines’ cached content. To index any web page, search engines retrieve its text, so a crude but readable version of almost any page can be found there. For a long time, Google’s cache was the most accessible, but in early 2024, the search giant removed the direct link to its cache from search results. The service still works, but accessing it directly is very difficult.
Therefore, it’s better to use browser extensions that make internet archives easier to work with. For example, if a link takes you to a deleted page or a defunct website, the Web Archives extension redirects you straight to an archived copy of this page at web.archive.org, archive.today, or perma.cc, or shows a cached version of it from Google, Bing, or Yandex.
How to save data from other online services
Besides web pages, there are many other online services — from photo albums and notes to social networks — that hold data you also may want to save. Of course, recommendations vary for different types of data and specific services, but for your convenience, we’ve grouped all related instructions under the backup tag. You can read about creating backups for:
And don’t forget to safeguard your backups against ransomware and spyware!
